RL is deep
RL is Deep
AI, is on a boom. I turn around and see preschoolers talking about the latest research papers in the community and how their desktop doesn’t have enough GPU computation power.
Sure, I may have exaggerated a bit but the situation is still pretty hyped up. With recent advancements in Deep Learning, experts have been able to defeat Pro-players in MMO games, the realization of Self Driving Cars has become seemingly plausible, Googles BERT has achieved SOTA in complex NLP tasks etc.
One area of AI research that has gained considerable traction in recent times is Reinforcement Learning. With Open-AI successfully defeating Pro teams in DOTA and DeepMind taking down the No-1 Player in Go, it looks like the machines are ready to take over.

The idea behind Reinforcement Learning comprises of an agent, through its interaction with the environment by performing actions, which receives rewards that provide it with an intuition about its performance and tries to learn from its mistakes.
This process is very similar to what happens in the real world and serves as a backbone for the conceptualization of RL.
Multi Agent RL
Considering the real world scenario, people need to work with other people to achieve their goals while being wary of each others position and have to act accordingly. This is team-work and is required in all aspects of life.
Building on this, Multi-Agent RL is a branch of Reinforcement Learning that aims in dealing with environments consisting of multiple agents where each agent tries to work through its own goals while having information of its counterparts and acts in such a way that benefits the whole system of agents rather than selfishly fulfilling its own goal.
Multi Agent RL is a topic of ongoing research because of the inherent difficulty of balancing the idea between efficient teamwork and self prioritization. This has been further stressed upon in a number of other research papers and blogs such as DeepMind, Berkeley , Open-AI etc.

Problem Statement
Our problem statement, Multi Agent Reinforcement Learning - Dense Path Planning (MARL-DPP), can be surmised as a Navigation Based Path Planning Problem. This area of research is mainly correlated with finding optimality among multiple navigating robots that interact with each other, providing each other information of their locations along with their destinations that gives rise to the “Navigation” aspect in the aforementioned problem statement.
Building on this, we have made our research relevant to this area of study and have built the mechanics of a complete world that focuses on the small intricacies present in a N x M square environment that allows us to define as well as customize said environment to our purpose providing us with a rich interface required for complex navigation among multiple robots.
Rules for traveling among different nodes of the environment, a framework for providing multiple destinations to the navigating robots, customizing locations that can serve as obstacles in the environment are some of the features that are available and can also be further developed to integrate some of the users own mechanics to serve their purpose.
The robots involved in Navigation are also provided with an orientation corresponding to the real world cardinal directions that allow the robots to “dock” themselves in the required position on reaching their respective goals as defined by the environment. The path planning process takes this orientation into consideration and provides the robot with optimal strategies.
The agents in the system have to collaborate and cooperate with each other in order to complete their respective tasks. This is stressed even more when the robots in the system are in a deadlock and have no choice but to create a balance between their own optimality and collaboration with other robots in order for efficient solving of the system.
Application
Multi-Agent Navigation is/can be used for various transport problems such as in warehouses and factories that involve coordination among robots for exchanging and delivering goods to each other. Another use case would be to resolve Deadlocks in traffic as well as solving Parking Space inadequacies for efficient utilization of space. Recently, MIT hosted a competition specifically tackling these problems.
Brief Introduction and Motivation
Over the years, RL has progressed through a number of different approaches to solve optimization problems but these approaches can be broadly categorized as Value Based, Policy Based and Model Based. Our current approach is dependent on the Value Based method as it offers a lot of benefits over other methods and will be elaborated on later in the post.
Value Based
A State in RL can be thought of as a screenshot of the environment at any point in time. It encapsulates any and all information that needs to be present and is required by the agents in the system to make informed decisions during the training process.
In Value Based approaches, we try to calculate and optimize the value function denoted as V(s). The value of each state is the total amount of the reward an agent can expect to accumulate over the future, starting at that state.
Q-Learning
The Action Value Function (or Q-function) takes two inputs: State and action. It returns the expected future reward of that action at that state.
Q-Learning is a tabular approach to RL which is used to calculate the Expected Discounted cumulative reward of an action in a particular State.
For an in depth explanation on Q-Learning, refer to the link below. Q-Learning explained
Why Q-Learning
Q-Learning is a model-free reinforcement learning algorithm. The goal of Q-Learning is to learn a policy, which tells an agent what action to take under what circumstances. It does not require a model (hence ‘model-free’) of the environment, and it can handle problems with stochastic transitions and rewards, without requiring adaptations. Q-Learning can identify an optimal action-selection policy for any given Finite MDP, given enough exploration time and a partly-random policy.
Implementing Q-Learning takes less time as compared to other algorithms and can be easily studied for debugging purposes as it does not contain any black box elements in its process. Because of all the above reasons, Q-Learning served as a perfect first algorithm to test the feasibility of solving our Problem Statement and gaining an intuition of RL in particular.
Also, Q-Learning can do some pretty awesome things like,
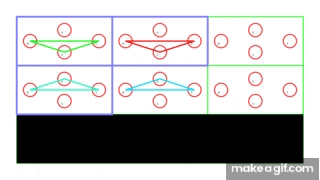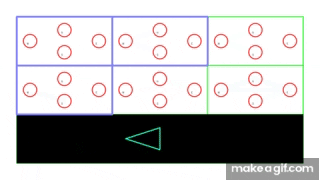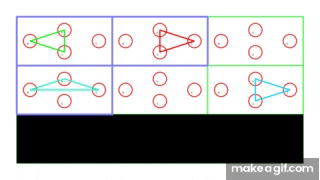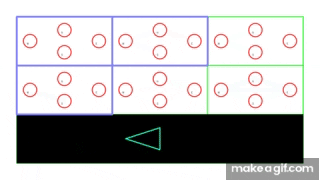
In the above GIF, each agent in the environment has a destination that lies in someone else’s optimal path and is thus impossible to solve without inherent coordination among every one of the agents.
Implementation Detail
Our Project focuses on solving the navigation of Multiple Agents (an agent can be understood as a car) in the environment using Q-Learning based approaches.
The Environment is a 2D square grid and consists of 2 floors. The number of rows and columns are predefined and can be customized to the users liking. The agents in the environment are assumed to be cars that need to travel to their respective destinations. Both floors have a single 3x3 block.

The numbering of the boxes in the environment are made to be in top-down fashion. For example, in the 3x3 environment image above, the green, blue and red cars are in boxes 5, 7 and 8 respectively. The black area below are boxes that can’t be accessed and serve as obstacles in the environment. The location of these boxes can be customized.
The circles in the environment represent the direction of the car, namely any one of the possible orientations N, E, W and S.
The blue outline around some of the boxes represent the possible destinations the cars can have. Each car will be traveling to any one of these destinations
State Representation
The State is a minimalistic representation of our environment at any specific point in time and encodes information necessary for training the agents.
For our environment, we have represented the State as a string which contains the source and destinations of the cars available in the environment. Based on the floor, the State uses D for representing the down floor and U to to represent the upper floor. The State can be interpreted by choosing a single car to be the Primary car and the remaining cars as the Secondary cars.
Concept of Primary and Secondary Car
The State is always written using the perspective of the Primary Car. The Primary car is an agent which is chosen out of all the available cars and has more information encoded in the State string than other cars.
Example of a State
Using the image above, let us assume the destinations of the 3 cars in order to write the complete State. Choosing the Green Car to be the primary car and the floor to be down we have, Green Car Source: D5W - - - - Green Car Destination: D2E Red Car Source: D8S - - - - - Red Car Destination: D4S Blue Car Source: D7W - - - - - Blue Car Destination: D1N
The State would be D5WxD2EzD7xD1zD8xD4.
The Primary Car information always comes first. As stated above, we use the complete information for the Primary Car but we don’t include the orientations of the Secondary Cars. Hence, for the Secondary Cars, their Box Numbers are sufficient. We use ‘x’ to differentiate between the source and destinations of a particular car and ‘z’ to differentiate among various cars themselves. After fixing the primary car in the beginning of the state, the remaining data is sorted in ascending order based on the Source values of other cars which is why for the above example, after fixing D5W and D2E in the beginning, we have the data for the Blue Car followed by the Green Car (D7<D8).
Reward Shaping
Our Reward function is based on the Breadth First Search algorithm which finds the shortest path among two locations.

Rewards
The reward values for any agent is based on the difference in the number of steps/actions it takes for the agent before and after performing an action.
For example, in the above GIF, lets assume we need to reach 4 starting from 1. The number of actions it will take to reach 4 from 1 is 2. If we perform an action and move onto 2, the number of actions required to reach 4 from 2 is 1.
Hence, the difference in the number of actions is 2–1 = 1. A positive difference indicates that we have moved closer to our goal after performing that action and a negative reward tells us that we are now further away from our goal than we were before.
We also provide a mandatory slightly negative reward indicating that every action the agent has to take tells it that it hasn’t reached its goal and epitomizes faster completion of its task.

Future Scope
For this project, we will try to tackle the following challenges in the future
Generalized Multi Agent training
We have successfully trained multiple agents on a 2D maze but since Q-Learning is a table based look-up method, it does not provide any kind of generalization to other environments.
Since the uprising of Deep-Reinforcement Learning, the problem of generalization has been under constant research. Future work will focus on implementing the current architecture from a Deep-RL perspective to solve generalization.
Deadlocks
A Deadlock is a condition present in a State where 2 or more agents block each others paths and are not able to move to their respective destinations. This results in either sub-optimality in the navigation of the agents involved in the Deadlock or results in a complete halting of the system of agents. Our current system is able to handle Deadlocks by saving such states and solving them separately but the current architecture can be improved in solving Deadlocks without any bookkeeping.
We will focus on solving this by re-designing the reward function or extending our approach to receding horizon planning.

If you have any thoughts, comments, questions, feel free to comment below or send me an email: air@dosepack.com
Cheers !